
关于数据可用性和纠删码的说明
编辑 2018.09.25:请参阅 https://arxiv.org/abs/1809.09044 以获取此文件的纸质版本。
为了理解数据可用性问题,最好首先从了解“欺诈证明”的概念开始。假设攻击者制造了一个以某种方式无效的区块(例如,后状态根是错误的,或者某些交易无效或格式错误)。然后,可以创建一个“欺诈证明”,其中包含交易和来自该州的一些默克尔树数据,并使用它来说服任何轻客户端以及区块链本身,该区块是无效的。凭直觉,人们可以认为这种欺诈证明只包含处理相关区块所需的状态部分,加上一些哈希值,以证明所提供的状态部分实际上确实代表了区块声称建立在其之上的状态。验证欺诈证明涉及使用给定的信息尝试实际处理区块,并查看处理过程中是否存在一些错误;如果有,则该块无效。
从理论上讲,欺诈证明的可能性允许轻客户端获得几乎完全客户端等效的保证,即客户端收到的块不是欺诈性的(“几乎”,因为该机制有额外的要求,即轻客户端至少连接到其他一些诚实节点):如果轻客户端收到一个区块,那么它可以询问网络是否有任何欺诈证明, 如果没有,那么一段时间后,轻客户端可以假设该块是有效的。
欺诈证明的激励结构很简单:
- 如果有人发送无效的欺诈证明,他们将损失全部存款。
- 如果有人发送有效的欺诈证明,无效区块的创建者将损失他们的全部存款,一小部分将作为奖励归欺诈证明创建者所有。
虽然这种机制很优雅,但它包含一个重要的漏洞:如果攻击者创建了一个(可能有效,可能无效)块,但没有发布 100% 的数据怎么办?即使可以使用简洁的零知识证明来验证正确性,攻击者发布不可用的区块并将它们包含在链中仍然是非常糟糕的,因为这样的事情的发生剥夺了所有其他验证者完全计算状态的能力,或者制作与不再可访问的状态部分交互的区块。接受具有未发布数据的有效区块还有其他不良后果;例如,用于原子跨链交换或硬币换数据交易的哈希锁等方案依赖于发布到区块链的数据将可公开访问的假设。
在这里,欺诈证明不是一个解决方案,因为不发布数据并不是一个独特的可归因错误——在任何方案中,一个节点(“渔夫”)有能力对某些数据不可用发出“警报”,如果发布者随后发布剩余的数据,所有在那个确切时间没有关注该特定数据的节点都无法确定是否是发布者恶意隐瞒数据还是渔民恶意发出虚惊一场。
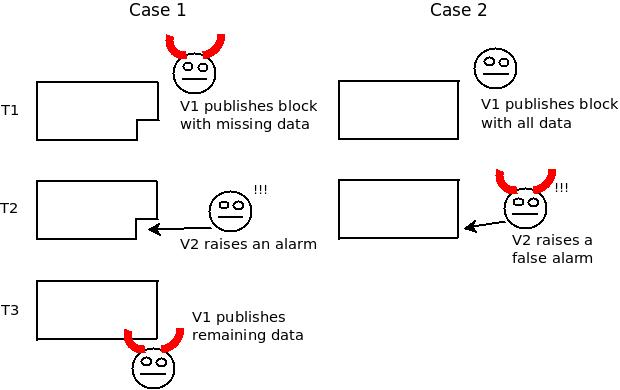
请注意,从只检查 T3 之后数据的人的角度来看,案例 1 和案例 2 是无法区分的。
这就创造了一个不可能的选择:
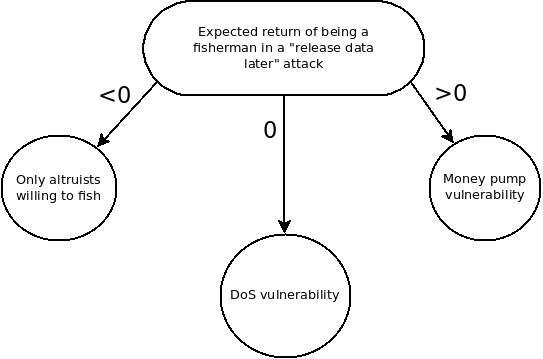
假设攻击者在进行攻击时隐瞒了数据,等待渔民捕获数据,然后立即释放数据。在这种情况下,渔网的回报是正的吗?如果是这样,恶意渔民发出误报就是一个资金泵漏洞。奖励为零吗?如果是这样,这是一个免费的 DoS 漏洞,可以用来强制节点下载区块链中的所有数据,从而抵消轻客户端或分片的好处。奖励是负数吗?如果是这样,那么成为渔民就是一种利他行为,因此攻击者只需要在经济上比利他主义的渔民更持久,此时他们就可以自由地包含数据不可用的块,不受阻碍。
一个自然的解决方案是让轻客户端在接受一个区块为有效之前验证它的数据可用性,但要概率地这样做。轻客户端可能会随机选择一个区块的 20 个块,尝试从网络下载它们(使用区块头中的 Merkle 根来验证每个区块),并且只有在所有 20 个请求都得到有效响应时才接受该区块。如果此检查通过,并假设有足够多的诚实用户进行这些检查,并且诚实的用户一起发出足够的请求来下载大部分块,则轻量级客户端知道大部分块的可能性非常高。
但是,仍然有非常危险的攻击可能发生在仅保留几百字节的数据中,并且这种攻击仍然会通过大多数客户端进行此类检查。为了解决这个问题,我们使用纠删码。纠删码允许将一段 M 个数据块扩展为一段 N 个数据块(“块”可以是任意大小),这样 N 个块中的任何 M 个都可以用于恢复原始数据。我们要求块提交到这个“扩展”数据的默克尔根,并让轻客户端概率地检查大部分扩展数据是否可用。
如果大多数扩展数据都可用,则轻客户端知道以下三件事之一为真:
- 整个扩展数据可用,纠删码构造正确,块有效。
- 整个扩展数据可用,纠删码构造正确,但块无效。
- 整个扩展数据都可用,但纠删码构造不正确。
在情况 (1) 中,该块是有效的,轻客户端可以接受它。在情况(2)中,预计其他节点将快速构建并中继欺诈证明。在情况 (3) 中,预计其他节点将快速构建并中继一种专门的欺诈证明,以表明擦除码的构造不正确。如果轻客户端在一段时间内没有收到欺诈证据,它将以此为证据,证明该阻止实际上是有效的。
有关实现所有这些逻辑的示例代码,请参阅此处。
如果使用最简单的 Reed-Solomon 代码,不幸的是,上述方案中欺诈证明的大小等于整个擦除代码的大小。欺诈证明仅由 M Merkle 证明组成;证明检查算法验证证明,然后使用这些 M 块来计算剩余的块,并检查完整块集的默克尔根是否等于原始默克尔根。如果不是,则代码格式不正确。
以下是使用 256 字节块将一维 Reed-Solomon 代码应用于 256 KB 和 1 MB 数据的一些近似统计信息:
- 轻客户端证明的大小 (256 KB):20 个分支 *(256 字节 + 10 个默克尔树中间哈希 * 每个哈希 32 字节)= 11520 字节
- 轻客户端证明的大小 (1 MB):20 个分支 *(256 字节 + 12 个默克尔树中间哈希值 * 每个哈希值 32 字节)= 12800 字节
- 使用 C++ 编码所花费的时间 (256 KB): 2.4 秒
- 使用 C++ 编码所花费的时间 (1 MB):21 秒
- 验证欺诈证据所花费的时间 (256 KB):2.4 秒
- 验证欺诈证据所花费的时间 (1 MB):21 秒
- 欺诈证明大小 (256 KB): ~256-512 KB
- 防欺诈证据大小 (1 MB): ~1-2 MB
计算时间包括部分优化;~3/4 的拉格朗日插值使用 Karatsuba 乘法加速到次二次运行时,尽管多点评估仍在二次时间内进行;这是因为人们发现用于多点评估的次二次算法更难实现,并且具有更高的常数因子,因此实现它们被认为是一种不太值得的权衡。上述运行时也是在单个内核上完成的;所有涉及的算法都具有高度的可并行性和高度的 GPU 友好性,因此可以进一步加速。
通过使纠删码多维化,可以走得更远。在一个简单的 Reed-Solomon 代码中,原始数据被解释为一组点,表示多项式的计算,x=0,x=1 ...x=M-1;扩展数据的过程涉及使用拉格朗日插值来计算多项式的系数,然后在点 x=M ...x=N-1。我们可以通过将数据解释为正方形来改进这一点,表示多项式的计算 (x=0, y=0) ...(x=sqrt(M)-1,y=sqrt(M)-1)。然后,该正方形可以扩展到更大的正方形,最高可达 (x=2*sqrt(M)-1, y=2*sqrt(M)-1)。这降低了计算证明的计算复杂性,因为所涉及的多项式是低阶的,并且还减少了欺诈证明的大小。
在这样的模型中,我们为所涉及的数据结构增加了一些进一步的复杂性。首先,我们现在有 4 个 * sqrt(M) Merkle 根,而不是一个 Merkle 根,每个行一个,每列一个。轻量级客户端需要下载所有这些数据,作为轻量级客户端证明的一部分。对于具有 256 字节块的 1 MB 文件(即原始文件中 4096 个块,形状为 64x64,因此扩展版本为 128x128),这将包含 256 个 32 字节哈希值,或证明中的 8192 个额外字节。此外,所需的分支数量从 20 个增加到 48 个,以弥补 2D 擦除码更“脆弱”的事实。从好的方面来说,Merkle 分支的规模较小。
这样做的一个主要好处是欺诈证明的大小要小得多:欺诈证明现在由单行或单列中的 M 个值以及这些值的默克尔证明组成,验证证明的过程包括从这些值中“恢复”缺失的数据,计算默克尔根,并证明这与提供的默克尔根不匹配。请注意,欺诈证明者可以完全自由选择所提供的默克尔证明是来自行还是列的默克尔树;这允许欺诈证明涵盖畸形的行和列以及行和列 Merkle 树之间的不一致。
现在,我们呈现了 1 MB(4096 个区块)和 4 MB(16384 个区块)的新统计信息,仍然使用 256 字节的区块。请注意,这些是估计值;完全执行此操作的算法尚未完全实现。
- 轻客户端证明大小 (1 MB):48 个分支 *(256 字节 + 6 个默克尔树中间哈希值 * 每个哈希 32 个字节)+(128 个默克尔根 * 每个哈希值 32 字节)= 25600 字节
- 轻客户端证明的大小 (4 MB):48 个分支 *(256 字节 + 7 个默克尔树中间哈希值 * 每个哈希值 32 字节)+ (256 个默克尔根值 * 每个哈希值 32 字节)= 31232 字节
- 使用 C++ 编码所花费的时间 (1 MB):7.5 秒
- 使用 C++ 编码所花费的时间 (4 MB):43.45 秒
- 验证欺诈证明所花费的时间 (1 MB):< 0.01 秒
- 验证欺诈证据所花费的时间 (4 MB):< 0.01 秒
- 欺诈证明的最大大小 (1 MB):6 个默克尔树中间哈希 * 每个哈希 32 个字节 * 64 个元素 = 12288 字节
- 欺诈证明的最大大小 (4 MB):7 个默克尔树中间哈希 * 每个哈希 32 个字节 * 128 个元素 = 28672 字节
简单通用的方法如下。每个顶级块都将包含纠删编码数据的默克尔根。数据将是以某种规范序列化形式构成顶级块的整个数据,包括每个分片的内容。每当存在可能具有可变长度的块部分时,要么用零字节填充它们,直到它们的最大可能长度(例如,由块大小或气体限制决定),要么在编码数据的开头使用表格来表示每个块的开始和结束。
然后会有两种欺诈证据。第一种是擦除码本身的欺诈证明,这取决于所使用的具体算法。第二种是欺诈证明,表明在擦除编码的默克尔根中提交的数据不遵循协议规则。例如,如果协议的规则规定 bazook 应该等于 kabloog 和 mareez 串联的 sha3,并且该块的规范编码将 bazook 置于字节 1000...1031,将 kabloog 置于字节 50000...50999,将 mareez 置于字节 55000...55999,那么就可以做出一个由指向 bazook 的擦除编码 Merkle 根的 Merkle 分支组成的证明, Kabloog 和 Mareez,人们可以验证这三个值不满足协议所说的它们应该满足的关系。
有点,但不完全是。PoR协议通常工作如下。Alice 创建一个文件,将其发送给 Bob,然后 Bob 使用一些技巧(通常还涉及纠删码和随机采样)向 Alice 证明他仍然拥有该文件。有时,鲍勃需要向卡罗尔而不是爱丽丝证明,并且对爱丽丝和卡罗尔之间可以共享的信息有一些限制。这些协议通常涉及MAC,或者在更高级的情况下涉及各种部分同态方案,包括椭圆曲线。在所有情况下,Alice 都被假定为可信的,从某种意义上说,我们假设 Alice 添加的任何“检查数据”都已正确添加,文件确实存在,并且 Alice 提供给 Carol 的任何类型的“公钥”都是正确生成的。
在我们的模型中,(潜在对手)Bob 本身就是创建文件的人。Bob 向 Carol 提交了一小段数据(想想擦除编码数据的 Merkle 根),Carol 正在寻求一种保证,即 Merkle 根确实代表了一条数据,它被正确构造,并且这些数据是可检索的。除了她自己之外,卡罗尔不信任任何人,并且保证有足够多的其他卡罗尔也在进行抽查,在他们之间,他们要么可以发现数据中的缺陷,要么可以下载整个文件。
一个关键的预期属性是共识 - 如果某个文件的 Carol 验证算法返回 TRUE,并且我们假设网络中有足够的验证客户端,那么 David 也很有可能,也许在基于网络延迟的一段时间限制后,也会为同一文件返回 TRUE;不同的参与者不可能对结果产生永久分歧,即使 Bob 恶意制作和发布数据也是如此。
有两大挑战。
- 如果我们简单地采用二维方案并尝试使其具有更高的维数,那么将用于轻客户端证明的中间默克尔根的数量将变得非常大,而不是将这些默克尔根直接包含在轻客户端证明中,而是为它们做另一个数据可用性证明,这将需要更少数量的默克尔根。
- 如果证明非常大,那么我们不能依靠单个节点来做整个证明。相反,我们需要依靠某种协作的生成。然而,这使得故障识别更加困难;如果 X 行与 Y 列或 Z 轴不匹配,并且两者是由不同的验证者制作的,我们如何判断是谁的错?这可能是可以解决的,也许可以通过让验证者指出行/列/轴的“理由”,例如。他们使用的现有值的位掩码,然后可用于推断出哪一方有过错,但这增加了方案的复杂性。
是的。邻近性证明是一个简短的证明,可以添加到默克尔根中,该根在概率上(在菲亚特-沙米尔意义上)证明默克尔树中至少有很大一部分(例如 90%)数据在同一个低阶多项式上。有关 PoP 工作原理的详细说明,请参阅 https://vitalik.ca/general/2017/11/22/starks_part_2.html。
可以创建一个邻近证明,证明某个具有 2N 个值的默克尔根 90% 接近 N 次多项式,这证明存在一些数据接近的唯一数据集(N 个值)。用户可以验证此证明,还可以随机下载树的分支样本,以概率验证,例如,至少 80% 的数据可用。在这种情况下,任何两个通过相同测试的用户肯定会至少有 N * 1.44 个值,他们可以用这些值来恢复原始数据(也许用 Berlekamp-Welch 算法之类的东西来抵消错误),并且可以保证这两个用户恢复的数据是相同的。
这种方法带来的一个困难是,并非每个 Merkle 分支都会指向底层数据,因为邻近性证明可以容忍少量的故障;因此,证明任何特定数据段的成员资格都需要一个接近性证明,并证明该默克尔分支所呈现的值在同一个低阶多项式上。因此,这最终不如下面描述的进一步解决方案......
是的。SNARK 和 STARK 可用于创建简洁(即。O(1)-sized)证明数据的默克尔根构造正确,同时证明在块中执行的状态转换是有效的。这使我们能够使验证区块的过程在概念上非常简单。
假设标头的格式为 ,其中 是 STARK。该证明将证明是某些数据的默克尔树根,其中一部分数据是一组事务,而数据的其他部分是该数据的正确格式的擦除码;它还将证明在 之上执行这些事务将导致最终状态根哈希。请注意,要创建 STARK,创建者需要提供所有作为“见证人”访问的 Merkle 树节点,但这些数据不需要进入 STARK 本身。(prev_state_root, tx_root, post_state_root, proof, sig...)prooftx_rootprev_state_rootpost_state_root
要验证一个区块,客户端只需要下载标头,验证 STARK,然后随机抽取纠删码数据的一些 Merkle 分支。
可以使用递归 STARK(即STARK 证明其他 STARK 的有效性),允许协作创建擦除编码数据,解决了上述第二个问题。从理论上讲,这种方案可扩展性的唯一上限是网络周围的节点愿意自愿可靠地存储的数据量。
有点,但有局限性。假设一个块有 4 MB 的数据,每个轻客户端对每个 256 字节进行 20 次查询。如果在整个网络中,轻客户端少于 820 个,那么攻击者确实可以进行这样的攻击,并欺骗每个轻客户端相信该块是可用的,而实际上没有足够的数据发布来重建整个事情(实际上,您需要 ~1140 个轻客户端来弥补重叠, 如果纠删码是二维的,则更多)。此外,如果擦除码是欺诈性的,那么欺诈可能永远不会被发现。
因此,该计划取决于两个诚实的少数假设:
- 存在足够多的诚实的轻客户端,以至于他们的数据可用性证明请求的交集很可能等于足够多的擦除编码数据来恢复整个事情。
- 存在足够多的诚实节点,如果发现擦除代码的任何部分是欺诈性的,它们将生成并转发欺诈证明
现在,即使有超过 1140 个诚实的轻客户端,攻击者也可以决定响应其中前 1000 个客户端的请求,然后停止响应请求,从而欺骗几个节点。这可以通过匿名洋葱路由网络单独发送每个请求来克服,这样攻击者就无法分辨哪些请求来自同一节点。部分相互信任的节点(即相互信任可能不是女巫)如果任何请求失败,也可以互相八卦,允许其他节点尝试自己发出该请求;这样,如果一个区块被大部分节点拒绝,它就会被所有节点拒绝。
这是不完美的,但请注意,如果设计构造正确,那么许多事情必须同时出错,才能使方案失败。一个精心设计的可扩展数据可用性验证方案将有一个随机选择的验证者委员会对每条数据进行签字,因此诚实多数模型和诚实客户少数假设都需要失败才能通过不可用的数据。也就是说,确保数据不会分散得太薄,以至于诚实的客户少数假设成为实际问题,这可能是该方案确实存在的主要可伸缩性限制;即使它适用于千兆字节块,也不适用于 PB 级块。