



-
机器学习正在经历一场复兴
-
机器学习计算是世界上最重要的市场,< 7 年内可能超过美国所有 GDP 的 1%
-
这个市场由少数限制准入和收取租金的参与者控制
-
机器学习计算协议提供了一种可访问且具有成本效益的替代方案:确保每个人构建人工智能和计算自由的权利。
-
要成功,该协议必须满足 GHOSTLY 标准
-
如果人工智能要充分发挥其潜力,我们必须建立构建的权利
机器学习模型正在驾驶我们的汽车,测试我们的视力,检测我们的癌症,让盲人看见,让哑巴说话,并决定我们消费和享受什么。这些模型现在是人类经验的一部分,我们创造和管理它们的方式将塑造我们作为一个物种的未来。我们的信念是,每个人都可以使用的开放计算资源系统,是确保我们所有人都能由我们创建的人工智能系统代表的最佳方式。
很快,我们将能够一时兴起地召唤娱乐,根据我们的确切偏好和欲望塑造,并由我们说出的每一句话和我们表现出的每一个反应所塑造。我们将能够收看以我们自己和我们所爱的人为主角的永无止境的电视连续剧,观看我们最喜欢的英雄拯救我们选择的任何世界的动作片,观看 C 型光束在 Tannhäuser 门附近的黑暗中闪闪发光,并生活在我们周围不断变化和发展的数字世界中。
除了娱乐之外,我们的生活将因持续的概率反馈而丰富多彩。我们将拥有个性化的基础模型,充当外部存储器,消耗我们消耗的信息,并学习通过RLHF来近似和增强我们的内在想法。我们将适应存储信息的新方法——就像我们适应搜索引擎一样——存储检索的密钥,而不是信息本身。历史人物将被他们留下的印记重新唤醒,我们的亲人将通过知道他们所知道的聊天系统继续生活,人与机器互动之间的界限将在我们甚至没有注意到的情况下开始模糊。生物进化可能是缓慢的,但社会和智力的进化是快速的,通过它,我们将变得与我们创造的智能系统没有区别。
这个未来需要巨大的计算能力,一个永远在线的原始处理资源网络,一个新时代的电力。利用这种力量并将其提供给每个家庭、每个设备和每个人,都应该通过我们所有人管理的网络来完成。不归任何人所有,但每个人都可以使用——价值流激励我们所有人向他们提供资源。永远。
0. 机器学习、计算和 AGI
-
机器学习 (ML) 是 AI 的一个分支,用于处理从数据中学习的系统
-
计算是设备每秒可以实现的计算次数
-
AGI是由人工手段构成的广义智能(即能够理解并存在于更广阔的世界中)的概念
在继续之前,最好先描述一下“机器学习”、“计算”和“AGI”的含义。
机器学习 (ML) 是人工智能 (AI) 的一个子领域。人工智能广泛地代表了任何自主做出决策的计算机程序,而机器学习通常是指可以学习如何从它们摄取的数据中做出这些决策的计算机程序。我们将做出这些决策的程序称为模型,并将知识灌输到其中的过程称为培训。
人工智能一直是一个反复无常的概念,因为我们对智能的共同定义会随着时间的推移而发生很大变化。例如,在 1950 年代中期做出(相对较差的)天气预报的 AI 模型与今天可以与您进行流畅对话的 AI 模型相比,不太可能显得很聪明。


计算能力,或“计算”,是机器为执行计算而转换的电力;最基本的例子是 FLOP(FLoating point OPeration),例如 1.0 + 1.0 = 2.0,通常以 FLOPS(每秒 FLOP)来衡量。就历史背景而言,1969 年将阿波罗 11 号任务送上月球的两台阿波罗制导计算机都实现了 14,245 次 FLOPS,而今天的 iPhone 14 实现了 ~2 万亿次 FLOPS。
FLOP 是计算的构建块,对于理解模型学习所需的计算复杂性(或“数量”)特别有价值。但是,用于训练模型的计算量也是一个流动的概念;部分原因是 FLOP 在最先进的设备上执行得更快/更高效(这意味着 10 年前 FLOP 的电气“成本”比现在更昂贵),但也因为 FLOP 并不总是计算能力的最佳衡量标准。例如,数据从内存传输到处理器的速率可能是计算任务中的主要瓶颈。尽管存在这两个问题,但 FLOPS 是量化计算硬件性能的便捷方法。
随着人工智能作为一个领域的发展,我们已经看到了模型的发展,从需要手动将人类知识硬编码到模型中的模板匹配等专家知识系统,到2001年自动发现图像中视觉特征的Viola-Jones等ML模型。如今,我们在执行高级 ML 任务时通常使用深度学习 (DL) 模型。这些模型是一类特殊的人工神经网络(ANN,或简称NN),(非常松散地)类似于人类神经网络,并在2010年代获得了突出地位,当时它们表现出令人难以置信的理解图像的能力。深度学习模型只是 NN,在输入数据和最终输出之间包含大量中间(或隐藏)处理层。这些层允许模型对输入进行推理,并通过建立以前见过的事物的“记忆”(称为参数)来建立自己对世界的理解。


我们现在看到的人工智能的快速发展几乎完全来自深度学习领域,这主要是由于模型的规模(深度)和用于训练它们的数据不断增加。简而言之,更多的东西通常会导致 1.减少错误,以及 2.可以应用于更复杂的用例。
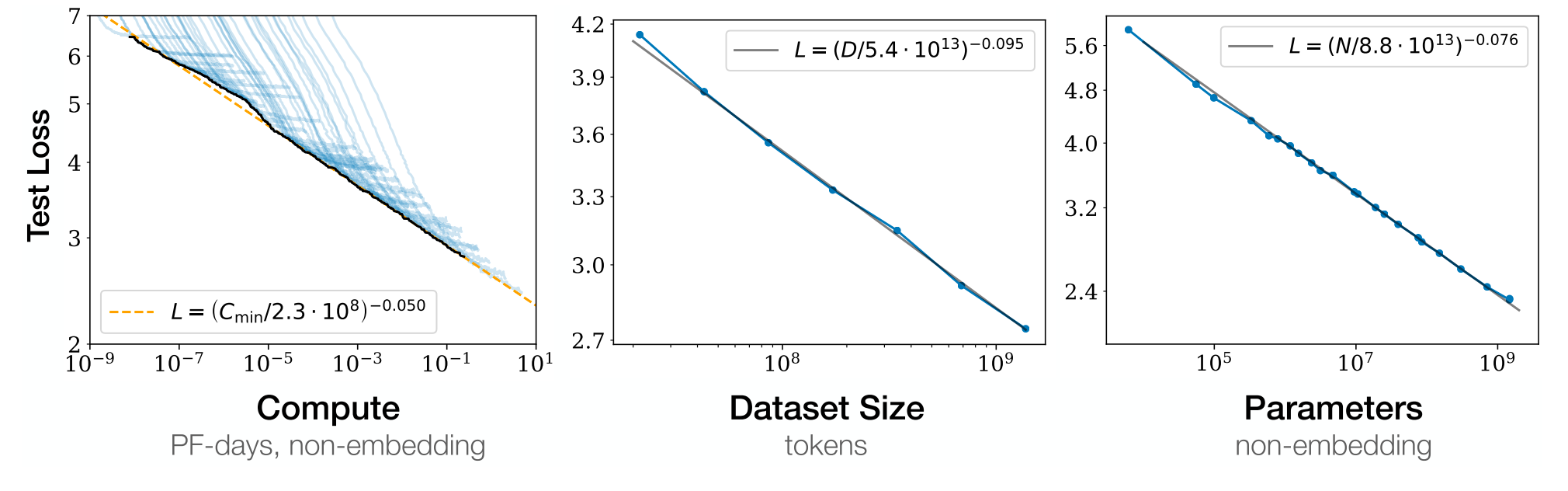
随着深度学习模型的规模迅速增长(大约每 6 个月翻一番),它们令人印象深刻的泛化能力(即将学习用于他们最初承担的任务以外的任务)导致了基础模型的创建。这些模型采用迁移学习的概念(使用预先训练的模型快速开始训练新任务),并将其扩展为创建模型的想法,该模型可以通过多个界面或单个通用界面(通常是基于聊天的)执行大量任务。基础模型和共享接口为人工智能提供了一种与世界交互的方式,这种方式超越了单个任务的高效执行,导致许多人将它们视为通用人工智能 (AGI) 的种子。
AGI可以是一个单一的大型模型,能够很好地概括世界,但它也可以是一个由不同模型组成的丰富生态系统,所有模型都在不断学习并自主地相互交互。前者代表了一条通往令人印象深刻的结果的快速途径,这些结果受到脆弱的偏见和难以调整目标的困扰。后者允许通过模型的自由市场进行元优化,由我们所有人通过我们的使用进行投票。如果您认为模型不能代表您的思维方式,请创建一个新模型!
1. 全球最重要的市场
-
计算正在推动智能领域的新一轮工业革命
-
仅ML训练计算成本一项就可能在8年内达到美国GDP的1%
-
硬件高度集中,价格被现有企业哄抬
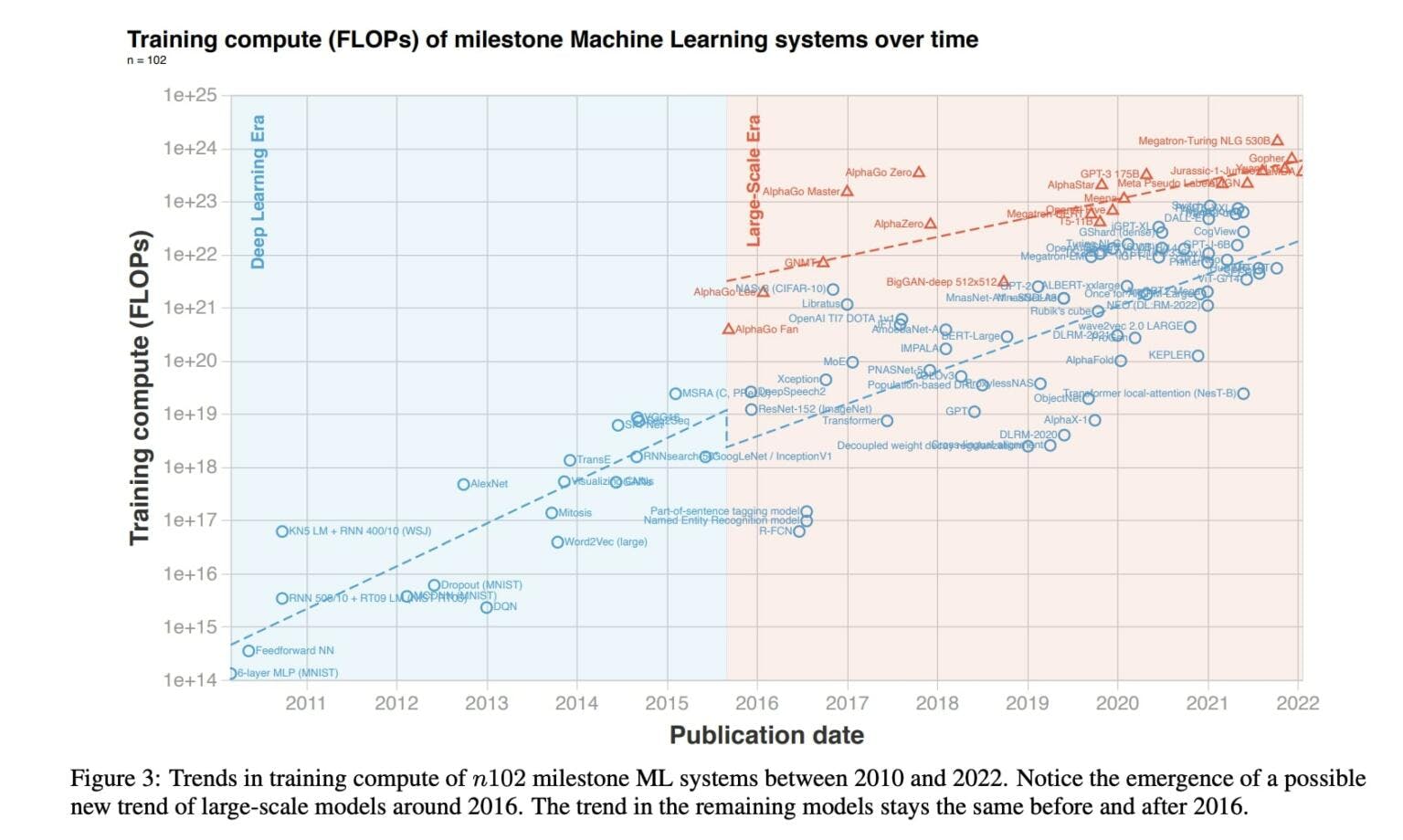
自 1760 年代以来,我们经历了大约三次工业革命:从蒸汽开始,然后是电力,最近是由互联网推动的信息革命。很明显,我们正处于另一件事的风口浪尖——一场智能革命——甚至更清楚它的加速剂是什么:计算。
回想一下,我们之前指出,人工智能系统性能的主要驱动因素是架构、数据和计算。架构的进步和数据都(相对)容易获取。学术出版传播了构建复杂模型所需的知识,确保新的突破在发现后不久就被每个人理解和使用。数据现在无处不在,对复杂的人工标记的需求正在消失,取而代之的是无监督和半监督的训练方法,这些方法可以简单地通过处理大量未标记的开放数据来创建丰富的嵌入空间。
那么,计算呢?它在模型的训练阶段(当它们“学习”时)和推理期间(当它们做出预测时)使用。但是,前者的计算密集度明显高于后者。早在 2012 年,人们就发现在图形处理单元 (GPU) 上进行训练比在 CPU 上进行训练要好得多。这是因为单个 NN 操作具有高度可并行性;例如,在单指令多数据 (SIMD) 的范式下,矩阵乘法可以拆分为许多并发运算。用于训练 NN 的最常见硬件仍然是 GPU,但它们现在带有用于计算 NN 层的专用内核,称为 Tensor Cores。此外,几家公司已经开发了自己的专用深度学习 ASIC,在 [智能/神经/张量] 处理单元 (IPU/NPU/TPU) 的术语下加速矩阵乘法和卷积算子。

这种硬件很昂贵:Meta 的 2023 年 LLaMA 模型是一个大型语言模型 (LLM),是在 3000 万美元的 GPU 硬件上训练的。事实上,训练模型,并针对某些任务重新训练它们(“微调”),是革命中最资本密集的部分。自 2009 年以来,训练模型的成本呈指数级增长,因为计算能力的进步解锁了新的模型用例,这反过来又增加了需求。从增长趋势推断,仅模型训练一项就可能在未来8年内达到美国GDP的1%。今年,这场革命反映在世界上最杰出的GPU制造商英伟达的股价上:其市值历史上首次超过1万亿美元。
然而,目前真正从中受益的是云巨头。随着 2010 年对 HPC 的需求激增,AWS(亚马逊网络服务)推出了他们的第一个 GPU 实例(集群 GPU 实例 - 它有 Nvidia M2050)。考虑AWS当前的p4d.24xlarge计算实例 - 您可以按小时租用的服务器,其中包含八个Nvidia A100 40GB GPU。俄亥俄州实例的费用为 4.10 USD/小时/GPU。根据亚马逊的资产负债表和外部研究,交付实例的边际销售成本为 1.60 美元(相当于 61% 的毛利率),边际运营费用为 1.50 美元(相当于 2023 年第四季度的 24.3% 的运营利润率)。Microsoft云服务的毛利率更高:72%。
其他云计算巨头也纷纷效仿,引发了一场关于计算的“云战争”和一场保护硬件的竞赛。ARK Invest预计的计算相关硬件支出说明了这一点:到2030年将达到1.7T美元。
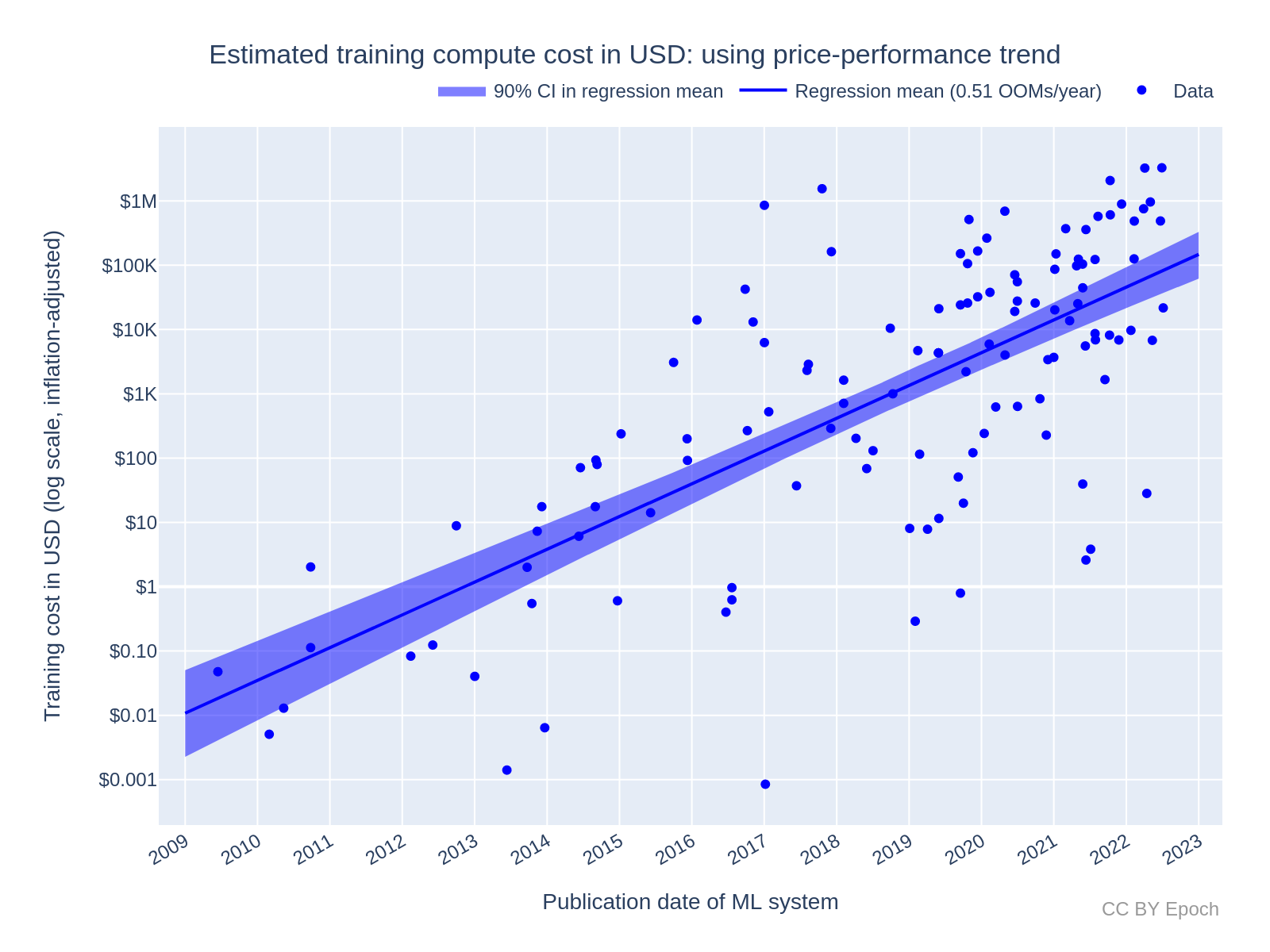
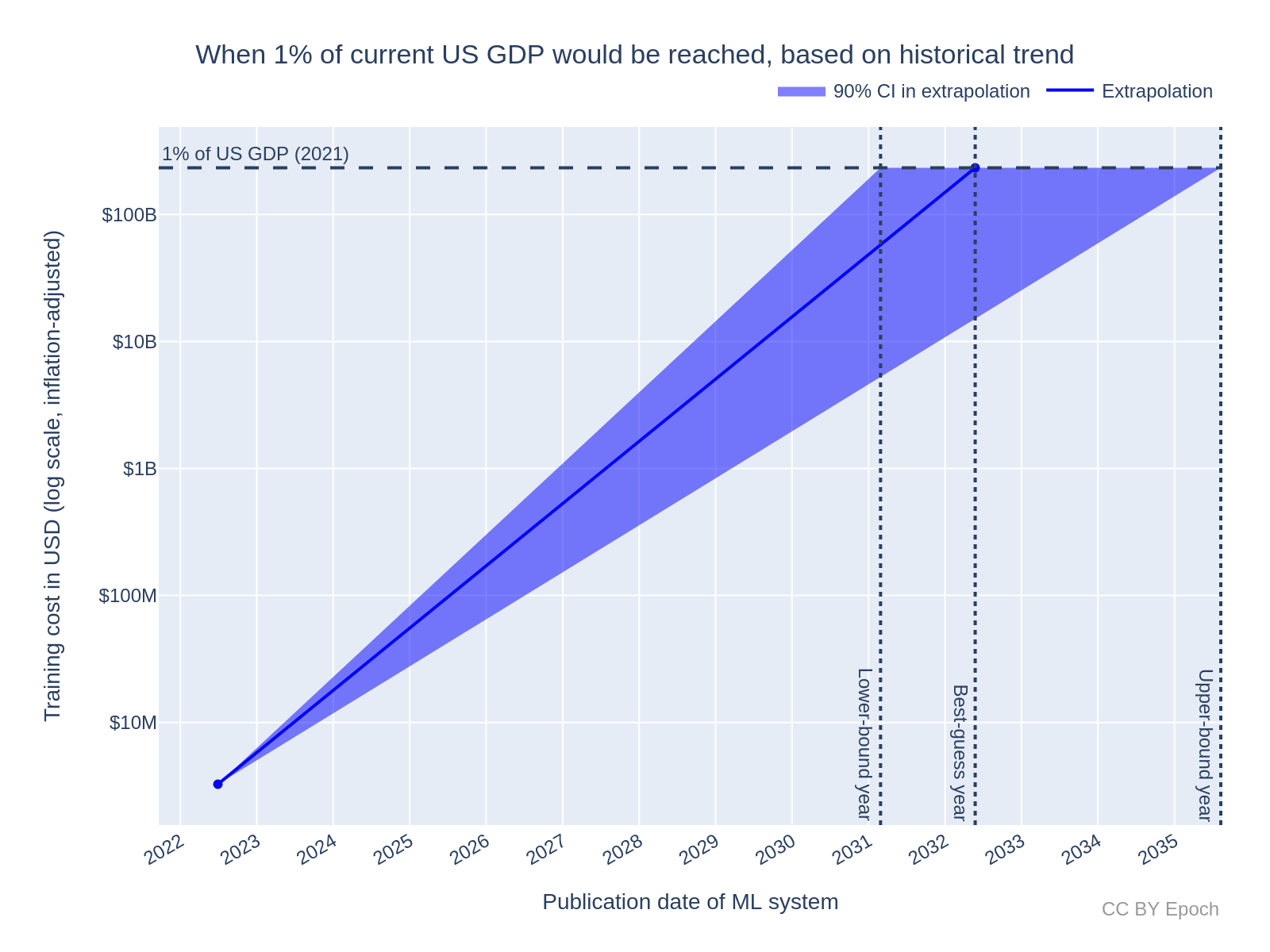
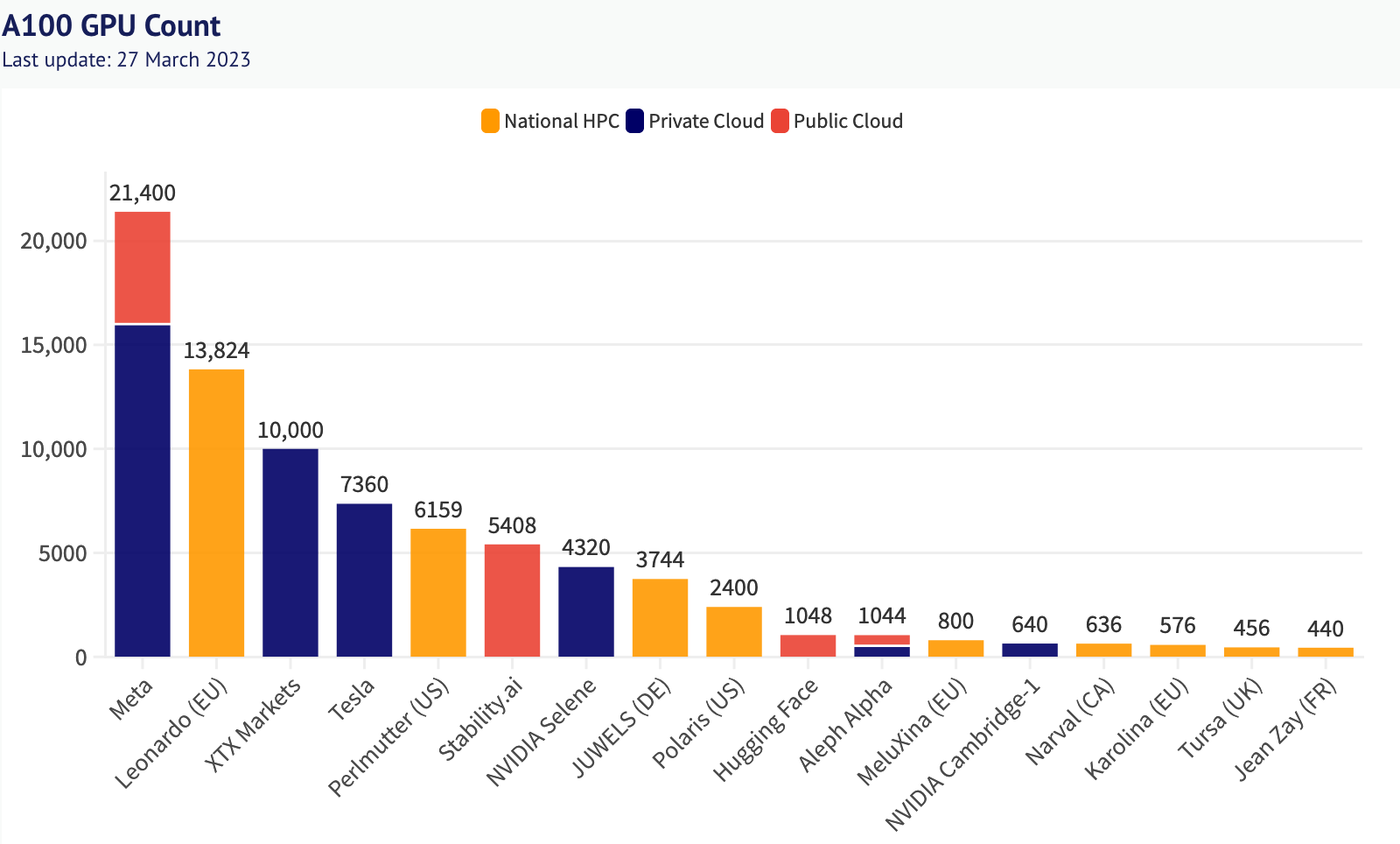
这种争夺硬件的争夺甚至在云巨头之外也是如此。考虑前面提到的 Nvidia A100 GPU 和更新的 H100——军备竞赛中的铀积累计算能力。这些 GPU 的所有权和集中在高性能计算 (HPC) 集群中具有很强的帕累托关系,并且严重偏向于资金充足的现有组织。拥有这种计算的好处(和后果)不容小觑。这就是为什么美国、欧盟和日本一再对中国实施“芯片”(半导体)制裁,以减缓他们建立AGI的能力。这也是为什么大型人工智能公司疯狂地游说以保持其对新市场进入者的优势的原因:控制计算就像垄断蒸汽动力、电网或互联网(人们已经尝试过)。
2. 机器学习计算协议
-
以前的分散式计算和文件共享网络为计算问题提供了另一种视角
-
通过使用由区块链保护的 P2P 网络,可以增加硬件访问并降低价格
-
要使这样的协议起作用,它必须满足GHOSTLY标准
可以做些什么?今年是 2023 年,成本正在失控,现有国家和公司正在通过立法锁定(和扩大)控制权,一些开发人员甚至难以访问单个 GPU。
如果我们停下来问“我们将如何以不同的方式处理这个问题”,我们会问什么问题?也许:
-
为什么我们要向云寡头支付我们在计算上花费的每一美元的 72 美分?
-
鉴于世界上未充分利用的计算的 exaFLOP(见下文),为什么我们只在集中式服务器群中训练模型?
-
如果我们愿意为此支付更多费用,为什么我们不能访问云巨头提供给他们首选客户的最先进的 GPU?
-
为什么 OpenAI 告诉我们,我们无法从头开始训练 LLM?
显然,所有这些问题的答案都是因为它们运作的经济模式(闭源、食利者资本主义)。此外,任何使用相同经济模型解决这些问题的尝试都注定只会导致不同的公司具有相同的结果和重复的循环。
然而,当我们回顾 HPC 的历史时,我们看到了另一条道路的种子:有 teraFLOP 甚至 exaFLOP 项目(exa 表示 1018,或 1 后跟 18 个零)在众包计算上运行。正如我们之前所指出的,早在谷歌囤积TPU之前,像SETI@home这样的项目就试图通过使用自愿提供的分散计算能力来发现外星生命。到 2000 年,SETI@home 的处理速率为17 teraflops,是当时最好的超级计算机 IBM ASCI White 性能的两倍多。SETI@home于 2020 年日落;然而,取而代之的是,Folding@home崛起了——众包 2 exaFLOPS 的志愿者计算来运行蛋白质折叠程序(用于更好地理解和治疗疾病)。
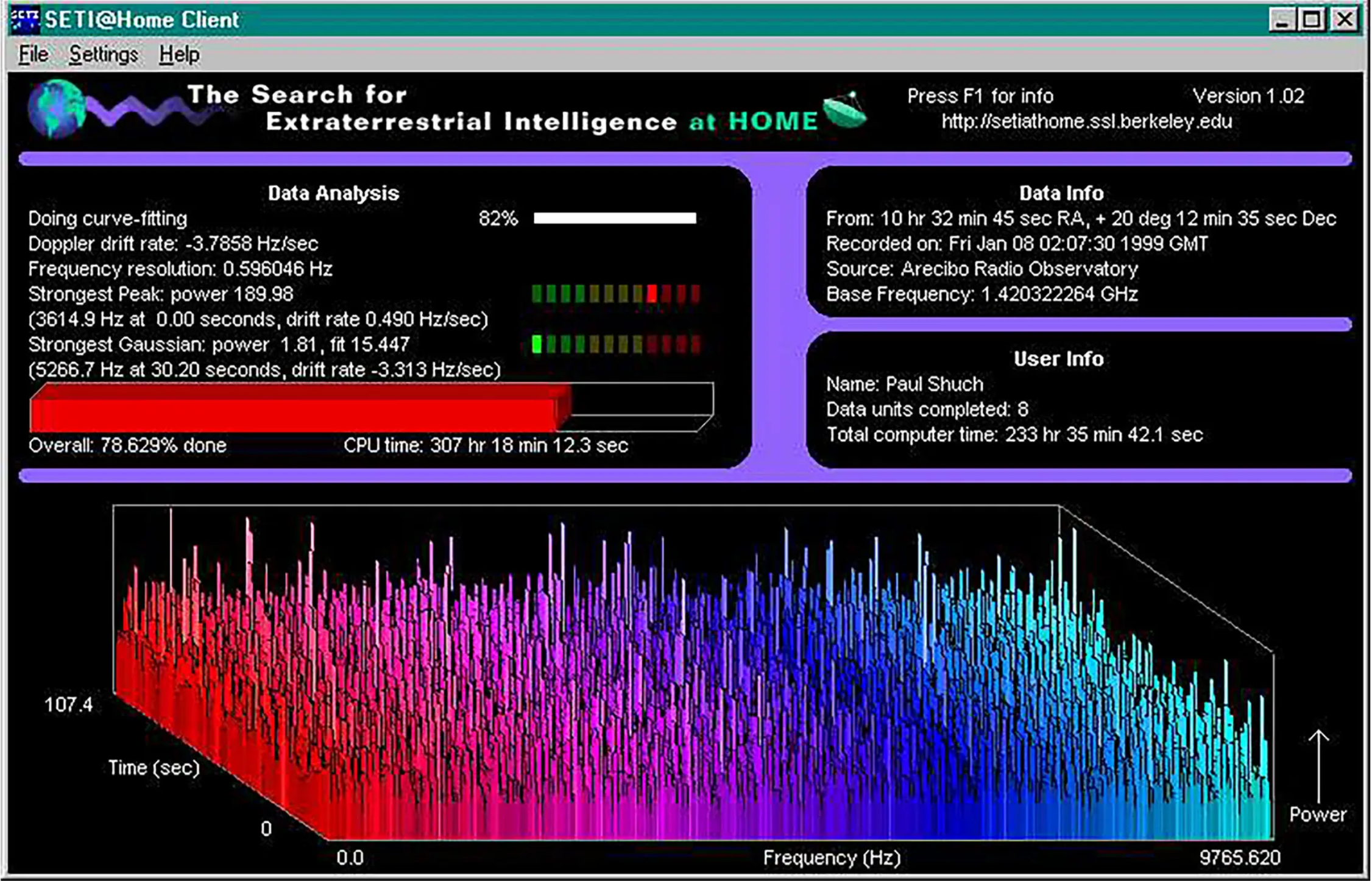
众包计算方法似乎解决了我们上面的一些问题:没有访问限制(任何计算机都可以加入网络,增加供应);这里不收取保证金;钱甚至不会转手。事实上,在互联网革命的其他地方,这样的相互关系也发生过。像 PirateBay 和 BitTorrent 这样的网站,它们在 2000 年代初期作为一种交换(通常是受版权保护的)媒体的点对点 (P2P) 方法而声名鹊起。尽管存在法律问题,但他们证明了P2P可以大规模存在(过去65-70%的互联网流量估计是P2P) - 只要用户得到适当的激励。
问题是,如果钱转手会发生什么?人们会有强烈的作弊动机。事实上,一些用户甚至欺骗SETI@home登上志愿者排行榜的榜首。为了解决这个问题,我们需要一个核心系统,该系统可以确保网络的经济激励,并验证是否正确提供了最低层提供的资源。我们需要一个新的协议。
这类似于比特币作者中本聪(Satoshi Nakamoto)在2008年试图创建一个协议时必须克服的问题,该协议将使虚拟货币能够在没有中介的情况下安全地进行交易。在这种情况下,提供的核心资源是共识本身,即对网络内状态转换结果的一致。无论人们对比特币的看法如何,有一点是明确的:它成功地激励了众包硬件加入网络并以某种方式行事。事实上,目前大约有 130 亿美元的硬件为网络做出了贡献(以今天的哈希率计算,假设蚂蚁矿机 S19 Hydro 设备),并最终因其安全性和交易验证而受到称赞。
在比特币证明协议概念可以创建并保护开放的金融系统之后,以太坊将该概念扩展到任意计算任务,包括以太坊虚拟机(EVM),该虚拟机(技术上是准图灵完备的)。这表明,通过这些相同的动态,我们可以建立一个由计算方组成的无信任网络来执行任何计算。
A downstream benefit of this protocol approach is that cryptonetworks like Bitcoin and Ethereum - which uses a more financialised and less energy-intensive consensus mechanism - do not charge margins. Instead, a small tax from every payment is returned to the network, destined to be used to maintain the network itself as directed by community governance.
An additional advantage of P2P for hardware networking is that the devices don’t need to be located in traditional data centres. Indeed, beyond the data centre GPUs like the A100, the following devices become available:
-
Custom ASICs: Like Graphcore’s IPUs - custom-built for machine learning - which could be combined into small clusters similar to Bitcoin mining operations.
-
Consumer GPUs: Like the Nvidia RTX series- mainly used for gaming but a mainstay of ML researchers in academia.
-
Consumer SoCs: Like Apple M2 - general-purpose chips with neural processing abilities. Even M1 processors can be used for training with performance comparable to a mid-range Nvidia RTX.

The greater supply and superior unit economics of such a protocol could reduce the price of compute by up to an order of magnitude. For example, the Nvidia A100 mentioned above can be purchased in bulk at $7,800/unit (US-customs cleared, December 2022). Hardware miners in the Bitcoin network typically rate opportunities on their ability to return the value of the hardware (note: the price of hardware can change in this time) over a certain time period, commonly 18 months. With a total power draw of 250w/h and assuming a constant price of electricity and maintenance of $0.10/Kwh in the United States, for a miner to be incentivised to provide deep learning computation they require a yield of $0.59/h to cover the machine and $0.025/h to cover electricity. This means they could provide compute for as little as ~$0.62/h → ~85% cheaper than AWS.
However, so far we’ve only considered protocols like Ethereum which work for small-scale computation - where every peer in the network performs the work (putting an upper cap on the computational complexity). If we wanted to perform large-scale computation using trustlessly-provisioned hardware to train a machine learning model, we would need to achieve one of two things:
-
Make the computations more efficient so that they can feasibly be performed by the chain; or
-
Prove that large-scale computations, performed off-chain, were performed as-specified to the satisfaction of the chain.
前一点是可能的,但由于前面提到的缩放定律,对模型造成了严重的约束;后者是一个令人信服的概念。在这种情况下,由无信任共识机制保护并能够进行任意小计算的区块链将能够在验证争议中取代受信任的第三方 - 只要计算的最终争议部分可以减少到合理的大小对于链执行。这使得验证系统,特别是验证工作的额外成本,成为协议成功的核心。
事实上,这样的协议需要满足六个定义原则,GHOSTLY:
-
泛化性 - 具体来说,是否可以提交自定义架构、优化器和数据集并接收经过训练的模型?这是 ML 开发人员的核心用户要求;只有当该训练模式成为默认的训练形式(脆弱/不太可能)时,将协议限制为单一类型的模型训练才有效。
-
异构性(供过于求) - 实现最大供货规模的核心是确保能够使用不同的处理器架构和不同的操作系统。如果协议需要散列(这在去中心化协议中非常常见),那么在不同设备上执行的计算必须产生相同的输出,即它必须是确定性的(或可重复的)。尽管输出的差异通常很小,但要实现深度学习的可重复性却非常困难,因为:
-
开销(低) - 以太坊区块空间理论上可用于训练模型;但是,与使用 Nvidia V100 GPU 作为参考的 AWS 实例相比,这会产生 ~7850 倍的计算开销。同样,即使是 Truebit 风格的博弈论复制方法也无法实现适当的低开销(仍然 ~7 倍)。任何核查方法都必须有少量的开销,以免抵消通过权力下放实现的单位经济收益。此外,FAT 协议通常会产生更高的开销,因为它们试图允许所有可能的计算。
-
可扩展性 - 依赖于专用硬件的协议,与普通机器学习研究人员使用的硬件不同,总是无法扩展到最先进的 (SoTA) LLM。例如,使用可信执行环境 (TEE) 可以部分解决信任问题,但代价是速度大幅降低。
-
无信任 - 如果网络需要信任,则:
-
它会产生扩展限制,因为需要受信任方来验证工作;和/或
-
在信任被打破之前,网络无法扩展到某个点以上,主导的经济结果变成了作弊;和/或
-
运营劳动力成本由对价格施加上行压力的网络承担(例如KYC检查)。
-
-
LatencY - 推理对延迟高度敏感(训练系统不太敏感)。这个问题的核心是模型并行性的概念;也就是说,如果您计算能力较强且延迟较差,那么是否可以将 1024 个 1 MB 模型发送到 1024 台设备,而不是将 1024 GB 模型发送到一台设备?你能把它分得更远吗?对于大多数 NN 架构,简短的回答是否定的。神经网络训练需要关于模型中其他地方发生的事情的上下文(状态依赖性)(与SETI不同,SETI是令人尴尬的并行的),因此需要一个系统,该系统可以:a)以最佳方式权衡计算容量与网络带宽;b) 以某种方式将模型分成更小的组件,而不会违反上述第 3) 点。
为了满足GHOSTLY原则,机器学习计算协议将SETI@Home的众包网格计算与以太坊的P2P验证和安全性相结合,以在整个世界的硬件上执行机器学习任务。
3.建造权
-
计算自由最好通过技术手段实现,而不是通过法律手段
-
去中心化的机器学习计算协议是构建与社会一致的人工智能系统的核心
-
这样的协议还通过防止寡头垄断来提高技术变革的速度
为了让机器学习模型以公平和公正的方式在我们的世界中扩散,我们必须建立构建权。不是作为政府强制执行的合法权利,而是作为一项技术权利,通过以新的视角进行建设——权力下放。这个权利非常简单——我们都应该能够访问构建新的机器学习模型所需的资源。我们正在与竞争对手竞争,这些竞争对手旨在通过控制一种从根本上改变我们社会的使能技术来主宰我们的未来。
对这项技术进行监管将创造新的垄断,而这些垄断将尽其所能维持其地位并增加其价值捕获。没有竞争的反馈循环,我们就失去了消费者声音的直接代表,必须依靠这些监管机构来维护他们的立场。当我们可以直接依靠市场来执行这项任务时,为什么要把这项任务交给一系列组织,每个组织都有自己的激励措施?
去中心化网络使我们能够改变激励结构本身,为资本主义强大的优化力量选择一套新的指导原则。通过建立协议而不是公司,我们可以抵制那些不可避免地将创新变成寻租寡头垄断的行为。
我们在 IPFS 等存储协议、Helium 等网络层和 Render Token 等利基计算网络中看到了这种趋势。至关重要的是,与存储不同,存储以集中方式进行扩展的成本非常低;网络,这受到梅特卡夫定律的影响;而渲染,这是一个相对小众的市场,机器学习硬件在任何规模上都具有明显的经济价值。网络上的第一个 GPU 与最后一个 GPU 一样有价值。
通过协议经济学,我们可以确保价值流由参与者网络管理,除了拥有有价值的资源之外,没有进入障碍。这些网络不会孤立分配或授权现有的版税,它们将参与者池作为要优化的共享资源进行管理。以这种方式在核心资源上分配价值,该协议激励改善资源本身的提供,而不是捕获更多的分配。
去中心化网络不仅改善了经济激励,还使我们摆脱了对我们消费的内容甚至我们的个人通信本身的专制控制。根据克里斯·迪克森(Chris Dixon)的说法,“但这种转变的好处将是巨大的。与其信任公司,不如信任社区拥有和运营的软件,将互联网的管理原则从“不要作恶”转变为“不能作恶”。
4. 未来
- 5年后世界将面目全非
在 5 年的时间里,开发人员不会考虑他们的模型将在哪里训练、服务器如何配置、他们可以访问多少个 GPU 或任何其他系统管理细节。他们只需定义模型架构和超参数,并将其发送到协议中 - 可以在单个 GPU、TPU 集群、十亿部 iPhone 或其任何组合上进行训练。
我们将回顾人类指导的人工智能模型训练,就像我们回顾祖先的手动工具一样;迈向自动化未来的必要但几乎难以理解的昂贵(就人力而言)的一步。
通过构建分散的轨道来将计算传送到硬件并支付给参与者,机器学习计算协议将是一个无形的网络,为计算革命提供进入下一个规模水平所需的基础资源。现在,我们都依靠少数几家公司将计算访问权限滴灌给他们选择的合作伙伴。通过去中心化,我们可以在所有计算上创建一个自由市场,允许任何人支付公平的价格来访问他们想要的尽可能多的计算。这样的网络将使目前受限制的开发人员能够尝试新的架构、数据集甚至模式——最终创造出原本不存在的东西。
相反,我们都可以为网络贡献资源,为我们不使用网络时拥有的计算能力获得报酬。当我们的MacBook或iPhone正在充电时,当我们的游戏PC闲置时,当我们睡觉但地球的另一端醒着时,我们的设备可以为我们赚钱。通过以这种方式分散负载,我们可以利用闲置效率、更环保的电力来源、地理停机时间,并充分利用我们已经制造的资源。随着比特币开始代理全球能源市场——这也会做同样的事情——所有这些都以实际经济价值的工作为基础,由其他人要求和支付。
最终,这些其他人将是机器学习模型本身。它们生活在维持它们所需的核心资源之上的自组织基质上,将触发训练、推理,甚至创建新模型。通用人工智能将不是一个可以回答问题的大型模型,它将是一个活生生的模型生态系统,可以自己思考、复制,有朝一日超越我们的理解。重要的是,我们要为每个人开放地建立它——我们不能让人工智能的未来掌握在少数人手中,他们认为自己知道什么是最好的——我们都应该在这个未来中发挥作用。